The Hidden Systems Problems Behind SWE Model Evaluation
SWE model evaluation looks like a benchmark, but the hard part is actually environment orchestration, repo isolation, and grading correctness. Here is how we built a real evaluation system.
Most benchmark setups start as scripts. You run python eval.py against a dataset, wait for results, and move on. It is simple, works for one-off experiments, and requires no infrastructure.
But scripts stop working when you need repeatability, parallel execution, artifact storage, job tracking, and programmatic access from other services. You end up wrapping shell calls in more shell calls until the whole thing becomes fragile.
SWE-smith is powerful. It evaluates LLM-generated patches against real GitHub issues using actual test suites. But running it reliably at scale revealed something that most people do not expect: the benchmark itself is only 20% of the problem.
The other 80% is systems work.
Why SWE Evaluation Becomes a Systems Problem
When you run SWE-smith locally, it looks straightforward. You have a dataset, you have predictions, you run tests, you get pass/fail counts.
But the moment you need to run it multiple times, in parallel, across different models, with reproducible results that you can track and compare, everything changes.
The challenges are not about the benchmark logic. They are about:
-
Environment isolation. Each instance needs its own git worktree, fresh checkout, and clean test environment. Running multiple instances on the same machine causes branch conflicts and test pollution.
-
Sandboxing. The benchmark pulls real repositories, applies patches, and runs test commands that vary by repo. You need ephemeral, reproducible environments, not shared machines.
-
Artifact management. Evaluation produces detailed reports with pass/fail counts, test output, and failure reasons. Generation produces patch files. These need to be stored, tracked, and retrievable by job ID.
-
Job lifecycle. You need submission, progress tracking, completion detection, result retrieval, and failure handling. A script cannot do this reliably.
The benchmark runs in Python. But the infrastructure around it needs to be a real service.
Why Environment Grouping Beats Naive Parallelism
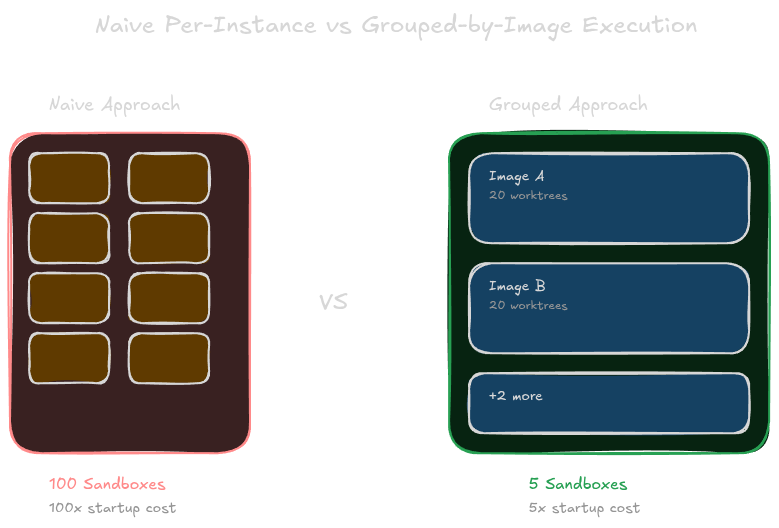
The first non-obvious lesson: do not spawn one sandbox per instance.
If you have 100 instances across 5 different Docker images, the naive approach is 100 sandboxes. The smarter approach is 5 sandboxes, one per image, running all instances for that image in each sandbox.
Why does this matter? Starting a Modal sandbox takes time. The startup cost dominates the per-instance cost. If you spawn 100 separate sandboxes, you pay the startup cost 100 times. If you spawn 5 sandboxes and run 20 instances through each, you pay the startup cost 5 times.
The grouping happens in what we call the Grouper. It maps each instance to a Docker image using the Registry, a database table that maps instance_id to swesmith_profiles containing the repo, image tag, and test command. Instances sharing the same image are batched together.
This is not just about efficiency. It is about correctness. Each sandbox receives a clean environment for its image. The instances inside share the same repo state but run in separate git worktrees to avoid branch collisions.
Why Git Worktrees Are the Real Isolation Primitive
The second non-obvious lesson: git worktrees, not branches.
Most people think about branch isolation when they hear about running multiple instances in one repo. But branches do not work well for this. You have to reset, checkout, and clean up after every instance. It is slow and error-prone.
Git worktrees solve this differently. A worktree is a separate working directory that shares the same .git database. You can have multiple worktrees checked out to different branches or commits at the same time, with no interference between them.
Inside each Modal sandbox, our Python worker creates N worktrees, where N is the concurrency level. Each worktree runs one instance. They are completely isolated. One worktree can be on a bug branch while another is reverted to HEAD, and they never collide.
The workflow for each instance:
- Create worktree at a fresh directory
- Checkout the instance branch
- Revert to the bug state (
HEAD~1) - Apply the predicted patch using fallback strategies: first
git apply, thengit apply --ignore-space-change, thenpatch --fuzz=5 - Run the repo-specific test command
- Emit JSONL results
- Clean up the worktree
This is the fundamental isolation primitive. Without worktrees, you cannot run instances in parallel inside a single sandbox. With worktrees, one sandbox becomes a multi-tenant execution environment.
Why Control Plane and Execution Plane Should Split
The third non-obvious lesson: two languages, not one.
We chose Go for orchestration because it handles concurrency well, provides strong typing, and integrates with our existing proxy infrastructure. But the actual benchmark logic lives in Python because that is what the SWE-bench ecosystem expects.
Go handles the HTTP API, job creation, dataset loading, instance grouping, sandbox spawning, result aggregation, grading, and artifact storage. It is the control plane.
Python handles git operations, patch application, test execution, and JSONL emission. It is the execution plane.
The split is not about technology preference. It is about separation of concerns. The control plane needs to be fast, type-safe, and integrate with our service mesh. The execution plane needs to be close to the toolchain, compatible with the SWE-bench ecosystem, and easy to debug in a sandbox.
This pattern is reusable. If you are building any benchmark harness that runs external tools, consider splitting orchestration from execution. The control plane stays manageable, while the execution plane stays compatible.
Why Grading Is Harder Than Running Tests
The fourth non-obvious lesson: passing tests is not enough.
Most people think the benchmark is done once tests run. But that is where the real logic begins.
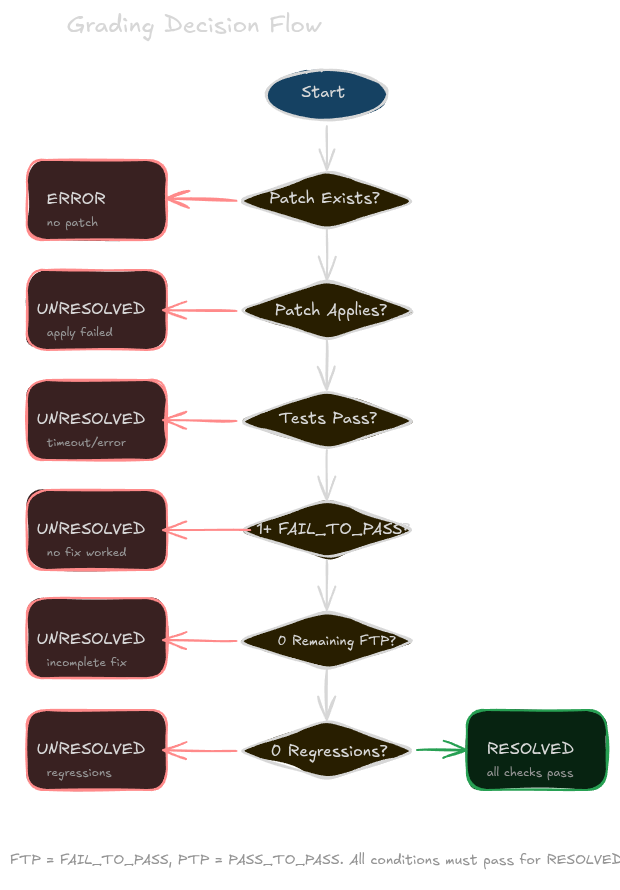
Our Grader parses test output looking for marked sections: >>>>> Start Test Output and >>>>> End Test Output. Inside those markers, it extracts test results. It then computes two categories:
- FAIL_TO_PASS: tests that were failing before the patch and are now passing. These are the ones that indicate the fix worked.
- PASS_TO_PASS: tests that were passing before the patch and are now passing. These should stay passing.
The resolution logic is strict:
- At least one FAIL_TO_PASS test must pass. Otherwise the fix did nothing.
- No FAIL_TO_PASS tests can remain failing. Otherwise the fix is incomplete.
- No PASS_TO_PASS tests can regress. Otherwise the fix introduced new problems.
If any of these conditions fail, the instance is marked unresolved or errored.
This is intentionally conservative. False positives, where a bad patch is marked as resolved, erode trust faster than false negatives. Once you claim a model solved a problem that it did not, your benchmark loses credibility.
Why Generation and Evaluation Share the Same Platform
The final lesson: do not build two systems.
Evaluation and generation look different on the surface. Evaluation takes predictions and produces reports. Generation takes instances and produces patches.
But under the hood, they share the exact same infrastructure:
- Loader: both load datasets from Hugging Face, S3, or local files
- Grouper: both batch instances by Docker image
- SandboxManager: both spawn Modal sandboxes
- JobStore: both track async job progress
- Storage: both store artifacts in S3
The only difference is the worker. Evaluation uses worker.py that applies patches and runs tests. Generation uses agentic_worker.py that runs OpenCode against each instance and extracts patches via git diff.
This sharing is the real win. Improvements to sandboxing, grouping, or artifact handling benefit both pipelines. You maintain one control plane, not two.
What We Would Improve Next
A few areas where we are not yet satisfied:
- Registry population: the
swesmith_profilestable needs manual curation. Automating registry updates from repo metadata would reduce maintenance. - Warm sandboxes: each job currently starts cold. Keeping sandboxes warm and reusing them for related instance batches would cut latency.
- Streaming results: clients currently poll for completion. WebSocket or server-sent events would improve real-time feedback.
- Cost visibility: we track job counts but not per-instance cost. Granular cost attribution would help optimize spending.
The Pattern Beyond SWE-smith
The core pattern here is not specific to SWE-bench. It is a template for running any git-based, repo-dependent benchmark at scale.
The key ideas:
- Batch by environment, not by instance. Startup cost dominates.
- Use git worktrees for isolation. Branches are too slow.
- Split control plane from execution. Use the right language for each layer.
- Make grading explicit. Passing tests is not enough.
- Share infrastructure between evaluation and generation. One platform is better than two.
If you are running similar benchmarks as scripts and hitting scale limits, the step from script to service is smaller than you might think.
The benchmark is the easy part. The systems around it are where the real work lives.